
In a tentative move into the AI-driven doc organisation and data extraction space – albeit focused on the consumer market – Google has launched Stack, an Android-based app that helps you to scan docs of all sorts, from receipts, to bills and bank statements, and which then automatically sorts them into categories and extracts key data.
First, thanks to Nate Schorr at the Legal Tech Fund for highlighting this. The next thing is: can Stack evolve into something more than a consumer tool to help people organise their bills and receipts? And, of course, the question that everyone is most interested in: is this Google getting into doc analysis in a way that may one day impact legal tech?
First, what is Stack? Basically it works like this: you download the app to your Android phone, you scan in a document e.g. an electricity bill, and it’s turned into a PDF, the system then conducts what appears to be visual pattern recognition and some basic NLP grounded presumably in lots of past machine learning to deliver a doc categorisation. It can also then extract key data from the document, at present primarily of the numerical variety. The various docs can then be backed up on Google Drive.
In short, it’s a fairly robust, but basic doc analysis, sorting and extraction system made for consumers that have very simple documents.
Clearly of most interest is that it picks out items such as due dates and amounts. That is where it gets interesting, as it’s this kind of data that very often is what legal tech doc analysis tools are also trying to find – although in their case it’s in long and complex contracts where written text predominates.
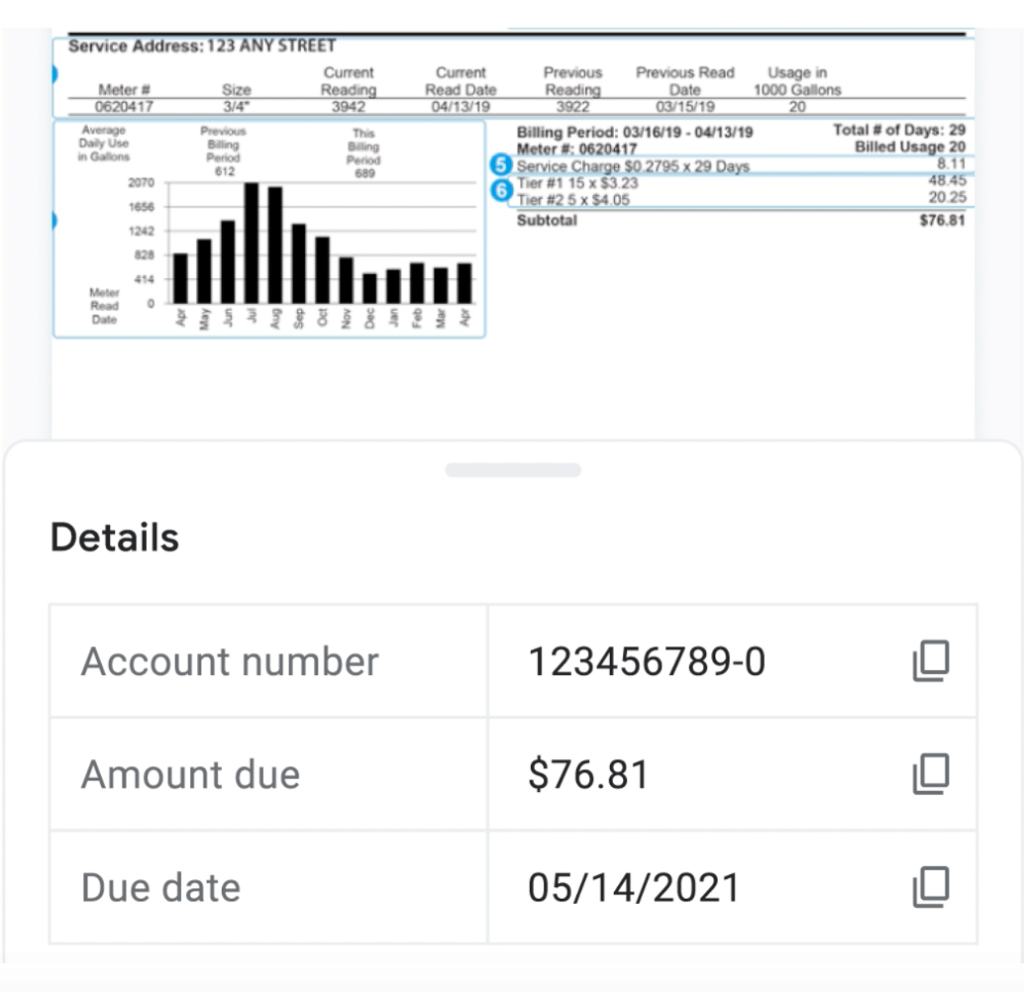
The challenge is that this has been made for very simple documents, in fact barely even what you’d call a document, and has been trained to spot very obvious data, e.g. a due date on a bill, which is usually heavily flagged on a single page.
That will be hard to translate to a complex contract of dozens of pages, mostly made up of text. So, legal tech companies need not panic.
But, in the longer term, could this be improved? For sure. With some additional work the same tech could be used to search for names, dates, parties and the like in longer, more complex docs full of unstructured data.
Moreover, there may already be use cases in terms of analysing financial statements related to a legal matter – if it can handle larger documents.
The reality though is that Google is developing this through its experimental Area 120 group because it has mass use potential. I.e. everyone has receipts and bills. Even if they are sent electronically they could (in theory) be loaded up via Google Drive and analysed by Stack once they were PDFs.
But, does Google want to build an app for the extraction of legal language? Or for that matter any special type of professional language found in documents? Probably not.
Although as covered before, fellow tech giant Amazon sells a Medical sector-based NLP tool for anyone who wants to buy it. A growing number of legal-adjacent companies are also making use of Amazon’s generic NLP suite. There is no sign Google is going to do the same…yet.
Could Stack already be of use to the legal world? It could be in some limited areas. We’ll need some lawyers to get out their phones and experiment.
Let us know if it’s of any use.
You can get the app (Android only) here.
Richard, nice write-up, thank you for surfacing this news. One of the big benefits for Google will be the access to millions of documents they can use to refine the AI models – much like captcha’s train object recognition. Of course, there will be thousands of bills that share a common layout – Verizon bills – but the sheer volume will guarantee they see more than any other document AI vendor could dream of obtaining. Once they have this baseline, they can more easily move into other spaces. Given the slow adoption of tech in the legal space and the TAM, I doubt we will be their first priority. Perhaps more important is how the Legal AI vendors will be able to leverage the advances they make.