
Legal services company, Epiq, has launched a pre-built NLP model strategy for use in eDiscovery and investigations. It’s a novel approach and offers pre-trained models to clients for litigation matters similar to how transactional review companies provide ‘pre-set’ NLP models for contract analysis. Artificial Lawyer spoke to Epiq about the new approach.
The short version goes like this: although most litigation and investigations review work is unique to each case, there are certain aspects that can be pre-modelled when it comes to identifying repeating key language or legal themes, which can then help speed up the review process.
Epiq has taken the view that they can accelerate the review process significantly by pre-building NLP tools for those repeatable use cases. In particular, they can also work with law firms and large corporates that have the same type of matter litigated again and again, e.g. employment disputes, or IP claims in the pharmaceutical industry, to further improve on those pre-built models.
Those models can then be stored by Epiq for future use – in effect creating an ‘NLP asset’ for use whenever a similar matter comes along. Exactly who would own these ‘NLP assets’ may depend on how they are created, but could potentially belong to Epiq, a law firm that they worked with on a project, or the end client that had engaged heavily with Epiq to build a bespoke model for their needs.
The reality is that much will depend on the type of matter. As shown in the diagram below, there are several gradations of activity, from very light touch before a project begins, e.g. ‘Cold Start’, to deeply working with a client, or law firm, to build a very tailored model, e.g. ‘Sizzling Start’.
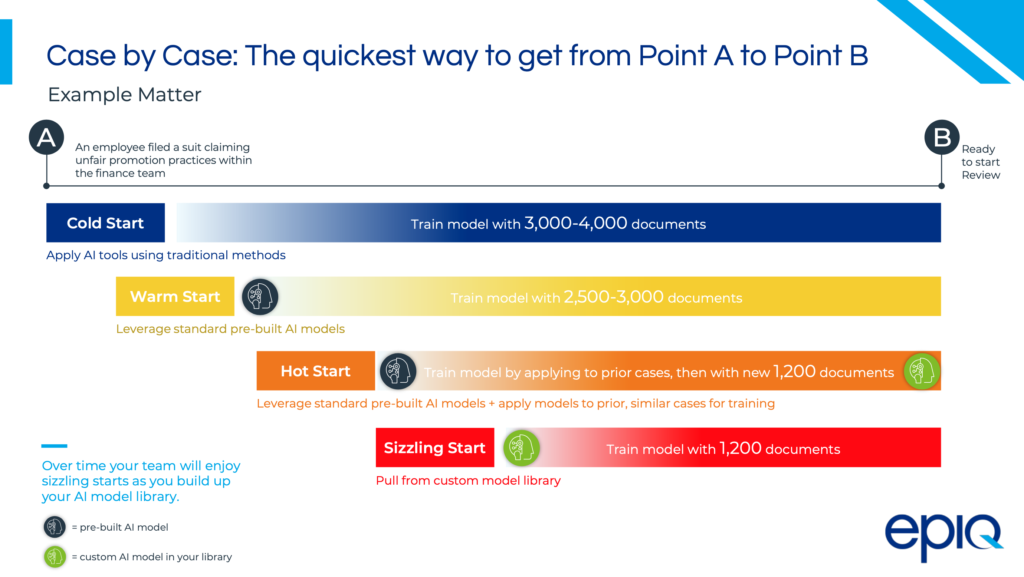
Aside from ownership the key development here is applying pre-built models to this area of work. As mentioned, pre-built NLP ‘recipes’ have long been seen as a way to speed up areas such as M&A due diligence. eDiscovery has tended to be more about handling the intricacies of each individual, and often massively complex, review project.
Moreover, these are different use cases, in M&A you are looking for key clauses that could be a risk to the deal, here you are seeking to isolate key documents that will then be reviewed further.
But, overall, they apply the same kind of logic – i.e. if we’ve already got the data to create useful models that can be used for multiple similar cases, then let’s use them, rather than starting from scratch each time. This will save time and drive efficiency.
As Eric Crawley, Managing Director, Document Review Services, explained: ‘We have been building project-based models on a case by case basis over many years. And it’s true that each matter is unique, but, there are enough issues that are common [to do this].
‘For example, there are core components related to privilege, or that relate to a specific client [which sees a lot of litigation and investigations], such as patent models for pharma companies, where we can build relevancy models.’
He added that they will be working with Reveal, as they have done in the past on some of these projects, but may work with other partners as well.
Scott Berger, Vice President, eDiscovery Managed Services, added: ‘We already have a lot of labelled data, but the pre-built models are refined from any data we can receive from the clients.’
‘Modelling is a way to leverage the data to reduce costs and risks [for the client],’ he added.
He also noted that there are plenty of law firms that want to win a steady stream of litigation work from major clients and having the capability to use these pre-set models – in partnership with Epiq – allows them to offer a better and more proactive service.
As to the exact business model, it’s clear that there are several options and the approach is still evolving, but Berger noted they could work as a ‘white label’ partner in the process, building the pre-set models for a law firm that worked regularly with certain large clients on frequently recurring litigation or investigation matters.
‘You could see us as a ‘captive’ for the law firm, where we empower the law firm to go to the next level,’ he concluded.
And to summarise what they will offer:
- Epiq will deliver both pre-built models that are plug and play as well as opportunities to create bespoke models unique to your matter type or your data working with our expert consultants.
- Once built Epiq will store the models and deploy on future matters for you.
- The models help maximize efficiencies, reduce costs, and get you to the most important data sooner.
All in all this is a very logical approach and makes a lot of sense. It also borrows a leaf out of the AI transactional review tool book. It’s interesting to see how approaches in one area of the market then trigger innovation elsewhere like this.
Another key area of interest is in terms of who will own the NLP assets. There is, from Artificial Lawyer’s perspective, a large potential market to become the owners of the best collection of models for use in certain types of matter.
And, one could argue that although there are several doc review companies in the transactional space that eschew the need for pre-training to get adequate results, the reality is that one of the major assets of NLP doc review companies is all the ‘crystallised’ training that their pre-set models have received over the years.
It’s therefore interesting to consider the growth of large companies in the legal sector that focus primarily on building pre-set NLP models across a very wide range of areas and jurisdictions, rather than worrying about the workflow system that the models are used within.
For example, we saw something similar to this with Apogee Legal, before they were bought by Seal Software – and which is now in turn part of DocuSign.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.