
The latest Vals Legal AI Report (VLAIR) has been published and focuses on legal research. It’s certainly got attention because key players didn’t take part and AI clearly ‘beat’ human lawyers. AL takes a look at what it all means.
First, what is Vals? It’s a US business working on the evaluation of AI systems. The focus here on legal research is just one of many projects they run. They brought in a group of legal AI companies, some human lawyers, and also tested against a general model. In this case the evaluated products were Alexi, Counsel Stack, Midpage, plus ChatGPT. At least one major vendor did take part, but then didn’t want its results made public (more on that below).
How does Vals compare human lawyer work with that of AI? They explained that they ‘establish a baseline measure of the quality of work produced by the average lawyer, unaided by generative AI. To achieve this, we partnered with a US law firm who supplied lawyers experienced in conducting legal research for client matters. The lawyers were asked to answer the Dataset Questions based on the exact same instructions and context provided to the AI products.’
And in terms of how it was all carried out, the ‘response collection took place over the first three weeks of July 2025. All questions were submitted to each product via API as a zero-shot prompt.’ So, companies – and general models – may have improved since then, as three months is a long time in genAI. Also, the test was not about how people used AI tools and the application layers that come with them, it was really laser-focused on a straight question/answer approach, without follow-ups.
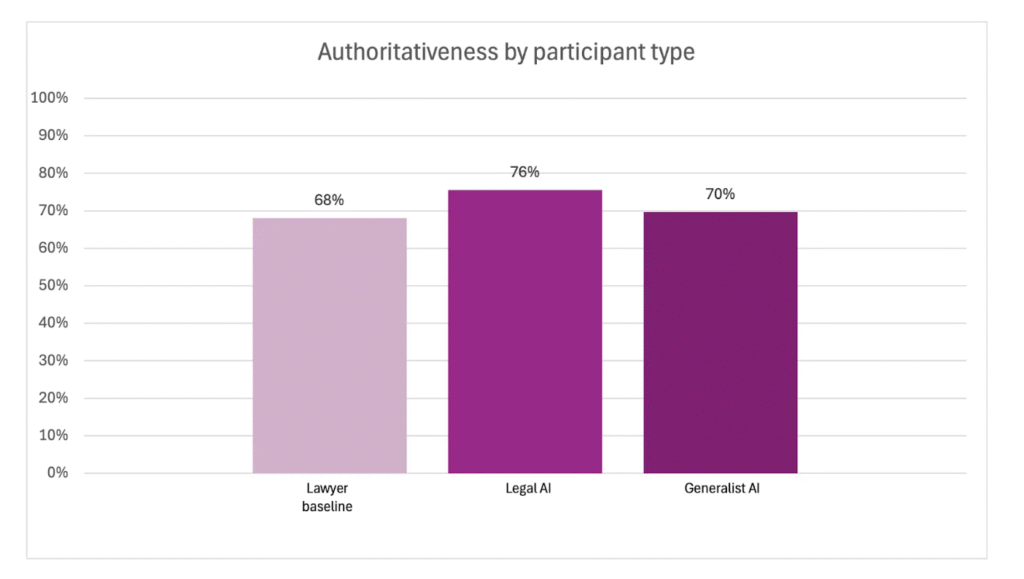
The overall finding is shown below, i.e. all the AI systems, including the general model, beat the human lawyers on 200 legal research question ‘distributed across a range of question types typically encountered in private practice’. They used three main criteria:
‘- Accuracy: whether the response is substantively correct with no incorrect elements (50% of average weighted score)
– Authoritativeness: whether the response is supported by citations to relevant and valid primary and/or secondary law sources (40% of average weighted score)
– Appropriateness: whether the response is easy to understand and could be immediately shareable with colleagues or clients (10% of average weighted score)’.
The AIs won on all three.
AL View
‘AI Is Better Than Lawyers At Legal Research’
OK, this is the big one that has gained the most attention. But, what does it mean? The ‘[test group of lawyers] were allowed to use all research resources and tools at their disposal provided they were not generative AI-based’. I.e. the human lawyers were also using digital databases packed full of legal information.
So, is this a surprise? On one level, no. Legal data stores are vast, complex, and can absorb huge amounts of time if lawyers are able to keep digging and digging. Given genAI’s strong language understanding capabilities, and the ability to tap this vast sea of data very quickly, it isn’t surprising that human lawyers were beaten here.
Also, when it comes to things like summarization, it would again – because of genAI’s language understanding skills – have been surprising if a test group of human lawyers had clearly beaten the AI.
If the lawyers had been strongly incentivised to spend considerable time on each and every question, and perhaps had a supervising partner there to keep saying ‘not good enough, go back and keep looking’, or ‘no, rephrase that, add more context, do it again’, and provide other high-quality feedback, then one would have expected the test group of lawyers to do a lot better. But, they were not in that situation, it appears.
OK, so, genAI tools are better at legal research tasks. What does this tell us? Well, it tells us that AI tools are good at handling tons of language. The questions, see below, didn’t ask the AI tools to then take that information and go to court with it, stand in front of a judge, or build a litigation strategy with the client. So, we are still far from ‘the end of lawyers’. Although, it may make some law librarians a bit nervous.
Moreover, is anyone really that sad that AI tools can provide very good legal research results? If AI tools can’t do well on this type of database-focused task, then they wouldn’t be much use for anything else.
Overall, A) this is not a big surprise, and B) this is welcome news. And C) we can add the caveats that the lawyers were not heavily incentivised to keep working on these questions, nor does a distinct research output equate to sophisticated legal skills in court.
That said, if you are a client reading this, and your law firm is charging you a lot for legal research, then you may want to have a conversation with them.
–
‘The Big Players Didn’t Play’
As noted, AL knows that at least one ‘big player’ took part and then decided it didn’t want its results shown – which is their prerogative. However, this opens up a range of issues.
- Are studies valid if only a small number of vendors take part, especially if the big brands are not there? The short answer is that having the big legal data players in the study would have made it much more valuable to everyone, because those are the ones that most lawyers use. Simple as that.
- Why didn’t the big players play ball? As with previous studies (by a range of groups), some companies have grumbled that the gap between the test and the publication is so great that the scores are not meaningful any longer, as three months is a long time in legal AI. That is a fair argument – although, the other vendors are all in the same boat. They could also argue that the tasks were better fitted to some companies and not their one. But, if you are in ‘legal research’ and the tasks are all about ‘legal research’, then surely this is a test you can do well at? One final reason is simply that the bigger brands have more to lose by comparing against other companies, even if they only fall short by 1% on a metric; and their top teams do not want that kind of message to go public….even if the end scores are only part of the value the big platforms provide. I.e. the application layer and all that goes with a sophisticated platform counts for a lot, and one metric in one study should not be seen as a final proof.
- Should the big players play ball? Well….yes. At the end of the day evals are only really useful if they test the tools that most lawyers mostly use – as well as the new kids on the block. Much as the ones tested are doing great work, we all know which tools law firms tend to use for legal research needs.
Do Tests Like This Give Us A Full Picture?
The reality is that a lawyer’s work is not just ‘find an answer to this specific question’. The work of a lawyer is within an ever-complexifying world, with multiple layers, client interactions, battling the other side’s lawyers, and much more. The ability to use AI to answer a legal research query is not the end of lawyers, not even close – not unless a client’s main reason for hiring a law firm is to do legal research for them.
Also, ChatGPT doing about as well as the legal specific tools can give a confusing impression. Legal AI tools will come with a dense application layer, providing a range of additional benefits, from UI/UX made for legal needs, to RAG systems, to workflow management, to connecting to a dozen other legal ‘skills’ and having all of that available in one place, and connected directly to your DMS and other data stores.
Could a law firm use just ChatGPT on its own for these types of question? Yes. As shown, the results are good. But, we should not ignore the points above. That said, it puts pressure on all legal AI providers to offer more than a ‘point and shoot’ capability. To add value above and beyond what a general model can do – especially now, as they widen their offerings – means to provide something special. And that’s a good motivator for the sector as a whole.
Overall, as noted by AL before, we need more than one study every now and then. Accuracy and its related values is a destination that we are travelling toward, and using a compass to get there. No test on its own is enough. We need a basket of evals. We also need to see evals as not so much as a test of individual companies, but as a statement of intent to the sector that lawyers want provable accuracy levels, and that those levels will keep going upwards.
Final comments.
AL asked Rayan Krishnan, of Vals, and also Tara Waters – the legal tech consultant, who is working with Vals, about A) the performance of general models vs legal AI tools, and B) about the limits of specific tasks as a comparator for what lawyers do more broadly. Here’s what they told AL.
Rayan – ‘My initial take is that the underlying models have improved very quickly. In particular they have been able to 1) leverage data available on the web very well and 2) limit their own incidence of hallucinations. This seems to have led to generalist models that can do legal research well. There are still some gaps, especially around their “Authoritative” score or the sources they use, but this may continue to narrow.’
Tara – ‘On the question of ChaptGPT’s performance, I agree as the latest models have much more up-to-date training. And we’ve seen the AI labs are starting to push their legal capabilities so one would think there is some proactive work happening there.
‘I personally didn’t find it so surprising that ChatGPT was up there on accuracy; I was mildly surprised its sourcing hasn’t yet been optimised for identifying proper legal sources first. TBH, that seems potentially an easy fix for the AI labs though (or I may be underestimating the complexity).
‘However, and somewhat relevant to your second question, it’s also important to note we didn’t test “research and prepare information for court filings” types of questions — which is really where we’ve seen the big issues in using public chatbots in the legal research context.
‘On your second question, I think there is general industry agreement that accuracy is not the only factor relevant in assessing AI capabilities, overall quality or value. However, it’s a huge challenge to assess the qualitative and user-led metrics at scale. I’ve had a few rich discussions on LinkedIn about this, and it’s something we hope to work towards solving.
‘At the same time, having a clear benchmark of metrics like accuracy and authoritativeness allows us to shift the question from “what does legal AI give us on top of the models” to “what do we want/need legal or any AI to provide us with and who’s got that on offer” and probably also “…and what is that worth to us”.’
–
Overall, a welcome study that gets us all engaged with the key issue of AI accuracy and encourages the legal AI companies to keep pushing forward. Thanks to Rayan and Tara, and the lawyers and companies that took part.
—
The full report can be found here (via main website).
—
Legal Innovators Conferences in London and New York – November ’25
If you’d like to stay ahead of the legal AI curve then come along to Legal Innovators New York, Nov 19 + 20 and also, Legal Innovators UK – Nov 4 + 5 + 6, where the brightest minds will be sharing their insights on where we are now and where we are heading.
Legal Innovators UK arrives first, with: Law Firm Day on Nov 4th, then Inhouse Day, on the 5th, and then our new Litigation Day on the 6th.


Both events, as always, are organised by the Cosmonauts team!
Please get in contact with them if you’d like to take part.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.