
Harvey has set out how it performed a new experiment to improve legal agent performance, that used ‘harness engineering’ to get far better results. That in turn shows a way ahead to how we may be able to really deploy legal agents at scale.
The findings are in a new paper published on X by Niko Grupen, Head of Applied Research at Harvey. OK, here we go.

This is how it went, at least in very broad terms:
- They ran an experiment to improve agent skill acquisition.
- It’s a combination of: autoresearch, where an agent runs its own experimentation loop; and harness engineering, where an agent’s capabilities are shaped as much by its environment and feedback loops as by updates to model weights.
- They ran the experiment over 12 tasks from Harvey’s internal agent benchmark.
- Legal tasks in this dataset span complex legal tasks like commercial lease review, complaint drafting, tax memos, disclosure schedules, due-diligence questionnaire responses, and many others.
- Each task comes with source documents, instructions, and a detailed grading rubric; and an agent needs to complete the task by creating real legal work products.
OK so far? Good. Let’s continue.
After the above set up, the experiment then did the following, which are the steps that really make a difference:
- ‘After an agent attempts a task, it’s scored by an LLM judge against its rubric with written feedback about what the agent got right, what it missed, and where its reasoning was incorrect.
- This setup is similar to an evaluator-optimizer workflow: generate, evaluate, refine, and repeat when the evaluation criteria are clear enough to support iterative improvement.
- A coding agent reads the judge feedback, clusters the failures, forms a hypothesis about what harness improvements would help, builds or edits the relevant components, and reruns the task.
- In practice, through this iterative process the agent develops its own legal-specific skillsets and behaviours, like cross-document review playbooks, stop hooks that validate deliverables before a run ends, structured fact sheets for drafting, and file-conversion pipelines that automatically produce the required outputs in the correct file type and format.’
And let’s recap: the agent does something, it’s judged, then the failures are analysed and improvements are suggested, which are then coded back into the agent. In short, it’s ‘self-learning’, or at least when there is a very developed ‘harness’, or one could call it an ‘educational infrastructure’ around it.
Of course, then you may well ask: if it’s teaching itself, how much did it learn? Well, a lot!
As the article sets out: ‘Baseline agents with generic harnesses are not able to solve these [legal specific] tasks well.
‘Across the 12 tasks, five tasks started between 2-7% success rate. After optimization, the average score across all tasks moved from 40.8% to 87.7%. Every single task improved.
‘Seven of the twelve finished above 90%. One reached 100% completion.’
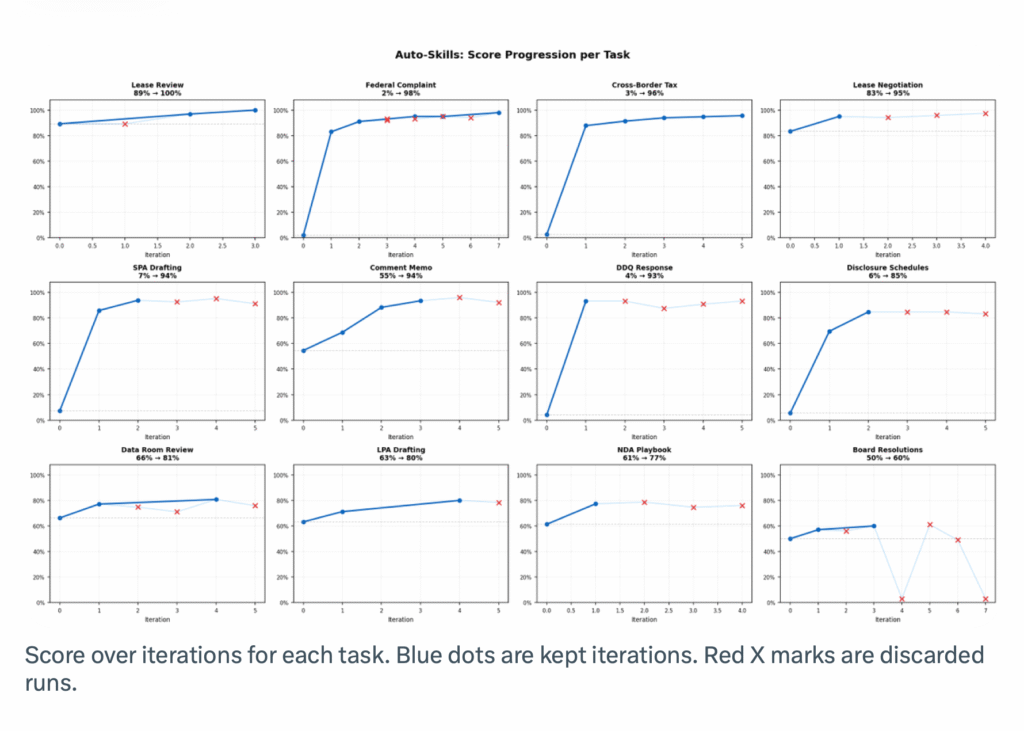
QED – it worked, mostly.
Conclusion
Harvey does however stress that: ‘This is a small-scale experiment. It does not generalise to all of legal work. But the core finding is meaningful: given input/output examples and a grading rubric, we can auto-generate agent toolkits that meaningfully improve agent performance.’
And importantly: ‘When the rubric is high quality, the agent can hill-climb surprisingly far.’
Grupen concludes that ‘Humans steer. Agents execute’. I.e. human lawyers set things up: the task, the rubric, the expectations, and perhaps where they may want to do some final quality control, but operating within this is the agent – which as shown – is not just doing the task, it’s capable of learning from doing the task, not just by a small margin, but by a huge margin of improvement.
AL has got to say that this is the way ahead for legal AI. Using AI as a chatbot is not enough to make an impact. We need real automation of complex legal workflows – and aren’t nearly all legal workflows complex…?
And if they are complex then an agent will need to learn how to handle them. Thus, the ability to really learn and then absorb that learning is going to be key.
As Harvey notes, this is by no means the end product, but it shows a way forward. It’s AL’s hope that in the months, and years, ahead we can hugely increase the complexity of what legal agents can do, and drive up accuracy results to the point where even really gnarly tasks can be confidently handed over to them – with of course the right level of human lawyer oversight. But, it’s oversight…..not the lawyer driving an assistant to do things every single step of the way. That’s the difference. And it’s a difference that really does ‘change the game’ for real this time.
You can read the full article on X here.
—
A Legal Tech Conference For All of Europe
Legal Innovators Europe – Paris – June 24 and 25.

There will be more news about the conference and key speakers as we get closer to June.
Look forward to seeing you there!
Richard Tromans, Founder, Artificial Lawyer and Legal Innovators conference Chair.
Note: the conferences are organised by Cosmonauts – please contact them with any queries.
If you would like to be a speaker at Legal Innovators Europe, especially if you are at a law firm or inhouse legal team in Europe – whether based in France, Belgium, Spain or Germany, or beyond…..then please contact Phoebe at Cosmonauts: phoebe@cosmonauts.biz
Note: if you are a legal tech company, please contact Robins: robins@cosmonauts.biz or Anjana anjana@cosmonauts.biz
–
And if you’re in the US and looking for the next major event to join after Legal Week, then see you in California this June!
Legal Innovators California, the landmark West Coast legal tech event, will take place on June 10 and 11, in the heart of the Bay Area, the home to many of the world’s leading AI businesses – and plenty of legal tech pioneers as well! More information and tickets here.

Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.