

This is a Guest Post by US-based Kripa Rajshekhar, the founder of legal AI company Metonymy Labs and an expert advisor to litigation funder/consultancy, Fulbrook Capital. This is Kripa’s take on where we are at present in terms of the development of legal AI and where he believes we are headed next, AKA ‘The Third Wave of AI for Law’. It also seeks to place today’s uses of AI in their historical context.
(Readers may remember Kripa’s Metonymy Labs recently partnered with Fulbrook to use AI analysis techniques to explore the world of patent disputes for the litigation funder, in what is the first deal of this type.)
It’s quite a big read, but it’s certainly guaranteed to get you thinking. If you agree, disagree or would like to follow up the debate with your own perspective on Kripa’s vision of the future, please let Artificial Lawyer know. In any case, please enjoy and many thanks to Kripa for this quality article.
Are you ready for the Third Wave of AI for Law?
Applications that aim at understanding and explanation, rather than just prediction? We’re headed back to the knowledge-first roots of AI in the 60s, but with the luxury of using a million times more computing power, and a billion times more data, to generate statistically sound stories that will have the power to explain, not just predict patterns.
This shift is consistent with the guiding principles that Josh Tenenbaum from MIT and his colleagues proposed to the broader AI Research community a few months ago. I think users of AI can now demand understandable models that explain data, and not settle for black box predictions. In addition to requesting your engagement to shape the development of AI, it is the main call to action I hope you take away from this note.
This article has three goals: (1) Introduce the Third Wave of AI, (2) Outline, in broad strokes, what this means for AI and Law, (3) Illustrate the path forward with a specific application of the approach: Metonymy Labs’ work to augment diligence with AI (#ADAI).
The Third Wave of AI
 Using DARPA’s framework for the evolution of AI, we see the First Wave of AI, which started in the 1960s. It included handcrafted knowledge systems where experts programmed rule-based systems to accomplish specific human tasks. Simple programming.
Using DARPA’s framework for the evolution of AI, we see the First Wave of AI, which started in the 1960s. It included handcrafted knowledge systems where experts programmed rule-based systems to accomplish specific human tasks. Simple programming.
In the Second Wave of AI, statistical learning (Big Data) was used to build large scale prediction systems to do literally unthinkable pattern recognition. These included applications like Siri, self-driving cars and IBM Watson. Most of AI development today is in this wave.
The Third Wave of AI is a nascent area where the output is not just a prediction that matches human performance, but rather a “story” or knowledge model, generated from data, which is valuable because it explains.
Like the founders of AI in the 60s, this wave focuses on: understanding and explaining the natural, social, economic processes behind the data Vs. just finding ways to beat/match humans on tasks using Big Data and prediction.
Good AI vs Bad AI
True to the 60s theme of ‘make love, not war’, this Third wave of AI avoids the conflict of interest between ‘man and machine’. To provoke debate on the values implicit in this technology: I divide these changes into (1) Good AI and (2) Bad AI (See: Footnote below).
Bad AI uses black-box actions/predictions to reasonably take human agency out of the loop. Good AI, empowers human decision making and action by providing understandable knowledge for action. The difference seems pedantic, but has teeth in practice:
- Good AI expands the user’s capacity to know more, faster, so they can choose to do more, faster. But the human stays in the observe-orient-decide-act (OODA) loop of intelligent behavior. Good AI improves the first 2 parts of the OODA loop for humans – (i) Observe: register more of our environment, (ii) Orient: Understand how best to contextualise it. This then helps the human user generate better Decisions and Actions.
- Bad AI technologies attempt to directly do more, faster, by emulating end-to-end what the human already does, but automatically, and usually through supervised machine learning. For performance reasons, the goal is usually to short-circuit the OODA loop.
Metaphorically, Good AI is analogous to speed learning German, from a great book/teacher, thus expanding the student’s capability. Bad AI is analogous to giving the student an easy to look up English:German dictionary. If we don’t see how these two forms are different, we will struggle to see the promise of Third Wave AI.
AI in Law Today Feels Uncanny
Like the field of AI in general, there is hype in AI and Law. Consider the title of an article cited in a 2016 survey of the state of AI in Law – “Law firm bosses envision Watson-type computers replacing young lawyers”. Most lawyers I’ve talked to are tired of this noise and are deeply sceptical. They don’t buy the hype.
Even numbers-oriented practitioners in the field, such as Chris Bogart, the leader of the largest litigation funder in the world is rightly sceptical of the notion of playing Money Ball in Law using AI and Big Data technology. Consider this snippet from his article, ‘Litigation finance, big data and the limits of AI’, published on April 20th, 2017:
‘ … much as we embrace technological development, we suspect the litigation finance business will for the foreseeable future remain a business that is still more dependent on specialized expertise and human judgment than it is on big data and AI.’
This is understandable. In the 1970s, a milestone AI and Law paper in the Stanford Law Review noted that: ‘Understanding and codifying the decision making processes of lawyers presents one of the greatest challenges of the proposed research.’
Almost fifty years later, their words are as relevant as ever. Like in many other professions, lawyers still learn mostly from other lawyers through decades of practice. This, after spending years in Law school, to learn sophisticated forms of thought and communication to make the learning possible. Billions of dollars in technology R&D spending, and tens of thousands of Legal Tech firms later, we aren’t any closer to codifying the Why? or How? behind our practices and systems of law. Many think this is impossible. But is it, really?
In recent efforts of firms such as CaseText, Lex Machina, Lex Predicts and Ravel we see attempts to use technology to help lawyers analyse the processes used in the practice of law. Answering questions like: Which venues have more settlements favorable to plaintiffs? How long does a typical case take to come to trial? Which attorney performs better in which courts? What prior cases does a judge usually cite? Yet, these efforts still struggle to address case specific factors that explain the decision processes, to address/raise Why? questions.
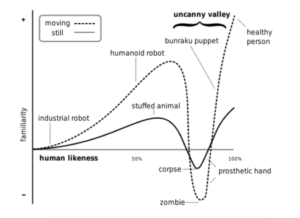
We technologists in the field need to acknowledge the two-headed elephant in the room – a lack of transparency and understandability. Second Wave AI technologies that have demonstrated success so far have focused on automation, efficiency and prediction. Applications such as self-driving cars, automatic translation, voice recognition, all use black boxes to solve prediction problems.
They aren’t transparent and they don’t help the user understand. They produce unauditable output, whether we like it or not! Prediction without understanding puts us smack in the middle of the AI uncanny valley that people in robotics have known about for decades. Some people tolerate this better than others. However, I don’t think we should have our lawyers or judges make decisions using predictions they don’t understand.
Thankfully, this will change in Third Wave AI. This is essential for law, as in many other professions. Addressing this deficiency of current AI is a promising way out of the uncanny valley.
The Path Ahead
Said another way: lawyers instinctively resist Bad AI.
Without technology expanding the scope of knowledge that an individual user has, we will not realize the true potential of AI in Law. We are in the earliest days of computationally mapping the landscape of our legal processes. Lawyers love more knowledge. Outside of information retrieval (which the legal profession embraced decades before most), lawyers have had little support from computer science (or AI) to model how a particular case relates conceptually or statistically to the applicable body of law and facts. In the future, AI must help practitioners navigate this terrain better. Over time, better probabilistic and explanatory models of the conceptual landscape involved can improve the quality of justice delivered and our collective access to it.
Towards this end, we might find inspiration in one of the first AI programs built in the 60s. It induced bonafide new knowledge, from vast amounts of data. It made actual discoveries of natural laws for scientists. It was called DENDRAL:
‘Using general principles, the program tries to relate the facts (data) to an hypothesis that clarifies the facts or shows why the facts should be expected … ‘
Its results uncovered new molecular structures from spectroscopic data. It was the first time that domain knowledge “discovered” by a computer program was published in a journal of its own field (chemistry), and not as a paper in computer science. Progress since then, in computational biology and now, precision medicine, attest to the power of this approach. We have a comparable opportunity in the area of AI and Law.
Techniques in probabilistic programing (a statistical style of programming that’s 100X more expressive than current languages for machine learning) and improvements in NLP (computational methods that derive meaning from language) are now available that can allow us to more efficiently discover models of legal relevance, argumentation and invariants in legal behavior from the troves of data coming online.
An Illustrative Example
At Metonymy Labs, we’ve taken a small first step, in this area. We have built tools that allow us to automatically discover relevance models from a large number of patent pairs that were flagged as being relevant in proceedings by a special US Patent Court (the Patent Trial and Appeal Board – PTAB). The models help us understand the forms of relevance used in legal judgements as we evaluate litigation funding opportunities. For example, let’s say two patents describe how to ‘fabricate’ a ‘semiconductor wafer’ with ‘more than two layers’. We could pose the question: ‘How many past rulings had a form of relevance with the following structure: Similar <OBJECT>, <CHARACTERISTIC>, <ACTION>?’
We could then test whether enough diligence has been done to examine all prior art that conforms to this notion of relevance. We could further ask the ‘meta question’ whether other forms of relevance were used in similar PTAB rulings and to what extent they are statistically significant in this particular matter. This is how a diligent lawyer would approach a case, but only if they had access to this vast amount of knowledge.
Today, they have to use heuristics and their experience to assure the client that the work is thorough, but they aren’t able to demonstrate (i) Why it is thorough and (ii) What the probability of omission might be given prior case law. This is the missing knowledge model that Third Wave AI can provide.
By testing coverage against typical models of legal relevance, we can help a diligence team better understand and quantify the extent and types of risk in a given case. This understanding of the legal landscape amounts to a summarization and reconciliation of millions of data points of relevance judgements with the case at hand. Impossible for a human to do without manually testing, potentially billions of pairs of documents for many, potentially novel, hypothetical forms of relevance.
This knowledge shapes future diligence by – raising potential questions (In what way is this patent exposed to an attack similar to those found in earlier cases?), offering avenues for further investigation (which forms of relevance should we next test given the diligence done so far?) and by locating specific documents for further examination. While we identify relevant diligence files 4X better than the state of art, saving orders of magnitude in research effort, the true value comes from helping us uncover the unknown unknowns in a case. Allowing us to pose the most crucial questions: What are we missing? Where should we look?
Conclusion
Still, we are only scratching the surface with this work. For example, an ambitious, but technically achievable, goal is to enumerate the universe of all prior forms of relevance in the patent law domain. A data-driven specification of the Person of Average Skill In The Art (POSITA, a legal construct frequently used in US Patent Law).
Key textual, logical and semantic relations are implicit in the millions of patent pairs that we’ve sampled from rulings over the last two decades. The heavy lifting – of data archiving, cleansing and indexing is done. This is high-quality, behavioral data that is ready to be mined. More probabilistic program development is needed, but this is an exciting opportunity for the field. It is valuable legal knowledge that simply does not exist yet.
We believe similar opportunities are available in other areas. Researchers like Kevin Ashley, from the University of Pittsburgh, and his team are doing exciting work in modelling forms of legal argumentation to help improve Veterans’ access to justice with their LUIMA system. With Harvard Law’s digitization project even more data will be available for such work.
The 1970s Stanford Law Review article I referred to earlier, foresaw that: ‘Computer science could enhance our understanding of the processes by which lawyers work and think. So far lawyers have not attempted to explore its relevance. They should.’ I believe the Third Wave of AI in Law, will deliver on their, almost 50 year-old, call to action. For all the reasons above, I hope we stop settling for prediction and demand understanding from our AI tools. And I hope that you are as excited as I am for what this Third Wave of AI and Law will bring.
Footnote 1: Justifying the provocative – Good AI Vs Bad AI split
Good AI has good social and legal checks and balances already in place. Bad AI badly needs new ones that we don’t yet have. Good AI will not compensate for Bad humans. Knowledge has always been used and abused by bad actors in all kinds of unforeseen ways. However, we have Laws that compel bad actors to take responsibility for their bad actions.
Good AI allows that system of justice to remain intact. Bad AI on the other hand has no human-in-loop and weakens human agency. Previous social experiments to save humans from themselves have not ended well – we must remain wary. I must also stress that what I call Bad AI may actually be important to build technologies for our collective welfare.
Well designed transportation systems that include Self Driving cars could save millions of lives every year. I call it Bad for only one simple-minded reason – no human in the OODA loop. If a machine observes and then immediately acts without human intervention, it needs to be designed and used with a level of wisdom that is many orders of magnitude higher than what we need for Good AI – where the human is necessarily in the loop.
References, research papers and images, in order of appearance in the article:
https://arxiv.org/abs/1604.00289
http://www.darpa.mil/attachments/AIFull.pdf
https://exhibits.stanford.edu/feigenbaum/catalog/qc929wq6500
https://en.wikipedia.org/wiki/OODA_loop
http://legalexecutiveinstitute.com/artificial-intelligence-in-law-the-state-of-play-2016-part-1/
http://www.burfordcapital.com/newsroom/litigation-finance-big-data-limits-ai/
http://www.jstor.org/stable/1227753?seq=1#page_scan_tab_contents
https://en.wikipedia.org/wiki/Uncanny_valley
https://en.wikipedia.org/wiki/Early_world_maps
https://www.linkedin.com/pulse/legal-information-retrieval-1962-kripa-rajshekhar
https://www.britannica.com/technology/DENDRAL
http://ebooks.iospress.nl/publication/45734
http://lil.law.harvard.edu/projects/caselaw-access-project/
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.
2 Trackbacks / Pingbacks
Comments are closed.