
 There is massive interest in innovation from within the legal profession.Law firms are creating innovation teams, clients are asking for evidence of innovation from firms and looking to innovate their own processes, lots of new start-ups have entered the legal market and traditional vendors are in acquisition mode as they try to respond to these challengers.All this has created the need for legal engineering, people with the skills and knowhow to bridge the gap between the capabilities of technology and the expectation of the user.
There is massive interest in innovation from within the legal profession.Law firms are creating innovation teams, clients are asking for evidence of innovation from firms and looking to innovate their own processes, lots of new start-ups have entered the legal market and traditional vendors are in acquisition mode as they try to respond to these challengers.All this has created the need for legal engineering, people with the skills and knowhow to bridge the gap between the capabilities of technology and the expectation of the user.

I want to pause for a moment and look back and understand why technology is disrupting the legal profession.
The Fourth Industrial Revolution
The first thing to say is that this disruption is not limited to the legal profession. We are entering/have entered the fourth industrial revolution and are seeing disruption across all levels of society and business. This disruption has, in the main, been driven by new technologies that have transformed our ability to combine, access, utilise and visualise information. The evolution of search on the internet provides an ideal example, which is familiar to all, to illustrate this journey.
In fact the rise of the internet, the subsequent massive increase in content and the absolute need to deal with the consequences of information overload have provided much of the impetus and opportunity to develop the new capabilities. However before we consider this story we need to appreciate how the nature of information has changed as we have moved from a world where information storage was primarily paper based to one which is digital and networked.
This video from Michel Wesch does a great job exploring this transition, just watch the first two minutes if you are short on time.
The key take away is the point that digital Information has no fixed form, so we can rethink information beyond material constraints. With this in mind we can view the evolution of digital information as a series of eras. In the first, PC era, the approach to managing information was based on re-creating a digital version of way physical information was managed.
For example, a book in a library can only exist in one place, on a shelf and its location is recorded in a hierarchical catalogue of broader and narrower topics. The file system on your PC replicates this as a file (book) is placed in a folder (shelf) and a hierarchy of folders (boarder and narrower topics) is constructed to catalogue the files.
However, as PCs became networked the volume of information increased and the file system became a shared workspace, the era of file shares. In a shared environment different people have different perspectives as to how the hierarchy of folders should be ordered and this led to the introduction of links between folders, alternative hierarchies, and the ability to embed links to files in folders, creating alternative filing strategies.
The next step was the emergence of the internet which is based on links between documents. This resulted in an increase in the amount of links between documents and an unstructured network emerges as an alternative to a hierarchical structuring of the file system. As the web opened up and moved from a predominantly read only environment, Web 1.0, to a read/write environment, Web 2.0, there was an exponential increase in pages and links between pages. The hierarchy was replaced entirely as it becomes apparent that the links alone were enough.
This was followed by Web 3.0 where the effort has been to contextualise the links between pages on the web. This represents a transformation from an unstructured network to a structured network. In a structured network, computers can interpret the meaning implied by a link between pages and/or the context of the terms/phrases on a page.
The ultimate realisation of this is that the web becomes something akin to a symbolic model of our knowledge which would introduce the next phase of the web’s evolution, Web 4.0, and the realisation of Sir Tim Berners-Lee’s vision of the Semantic Web.
The Evolution of Search
Having explored how the structure of digital information has evolved we are now in a position to understand how the end user search experience has developed and how this has been driven by exploiting the evolving structure of digital information on the web (see Figure 1). During the first few years, exploration of the web was dominated by categorisation of web pages and keyword search.
Both of these approaches just used the links between pages to identify the content that needed to be catalogued/indexed. In the case of the categorisation approach this meant building a hierarchical catalogue, essentially an electronic representation of a library (Yahoo even went so far as to introduce the bookshelf metaphor for top level categories on its home page), to impose order. This approach worked initially but failed to scale as the web grew.
As a result keyword search engines emerged, e.g. AltaVista. Keyword search engines work by counting the occurrence of ‘keywords’ in a document or on a web page and retuning ‘hits’ based on the keyword density. This approach scaled better than cataloguing, but ultimately could not cope as the web continued to grow.
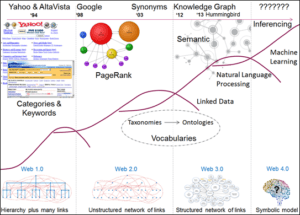
Figure 1: Changes in structure of the web.
In 1998, Google introduced the Page Rank algorithm and revolutionised search by massively improving relevance compared to previous search solutions. Sergey and Page’s insight was to realise that the number of incoming links to a web page can be used to score the popularity of the page. In essence, the more pages that link to a page, the more popular/important that page is. This information could then be used to rank the returned ‘hits’ and improve relevancy for users.
Google were able to achieve a dominant position in web search by incorporating analysis of the links in a network, not just to the pages in the network.
At this time, a Google search consisted of a straight match of the string of characters entered into the search box, and then the pages containing those characters returned as a list of ‘hits’ that were ordered based on the PageRank algorithm (see Figure 2). The next major development was for Google to move beyond simple keyword search and look to understand context and meaning both within the searches being performed and the content on the webpages being searched. This has been achieved by the development of new capabilities in vocabulary management, data modelling, natural language processing and machine learning that also underlie the renewed interest in AI.
The first step in this evolution was the incorporation of taxonomies, thesauri and spell checking into the search experience. This enabled features such as ‘did you mean this ….’ when a word is misspelled and the expansion of the search to include synonyms (words with the same meaning as the search term). For example, if you search for John F Kennedy you find the essentially the same set of pages as you do with a search using JFK.
These taxonomies and thesauri were then developed into ontologies, symbolic models describing concepts (people, places, companies, etc.) and the relationships between them. This allowed Google to identify search terms as things, rather than strings of characters. Combining these models with structured data from across the web (Linked Data, microformats, etc.) enabled Google to implement its knowledge graph(Figure 2). Armed with these resources Google could incorporate text analytics into its indexing process enabling the addition of context and meaning to both the text on web pages and the links between pages.
Through this process Google has been able to start visualising the internet as a structured network which is computer readable and on which AI services can be developed, of which Siri, Cortana and Google Now are early examples.
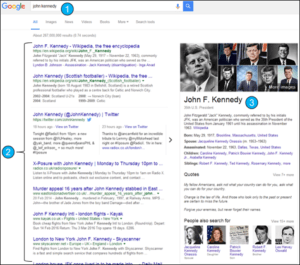
Figure 2: Anatomy of a Google search. 1) Search term; 2) a list of ‘hits’ that match the search term; 3) Knowledge Graph an aggregation of data from across the web about the thing search for.
Digital Information and Legal Engineering
So, having examined how the structure of digital information has evolved and deconstructed the Google experience, what have we learnt and how is this relevant to legal engineering? For me there are three key take home messages:
- Digital Information has no fixed form, so we can rethink information beyond material constraints.
- Increasing the structure/context within digital information is central to our ability to utilise it.
- The Google experience is created by realising the synergies that exist between multiple technologies.
It is these three points that lie at the heart of what legal engineering means to me. The chance to realise the potential to transform the way we work as a result of eliminating the material constraints associated with information and the opportunity inherent in the new tools that have emerged to exploit and manage digital information to give lawyers and others greater insights than ever before.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.
1 Trackback / Pingback
Comments are closed.