
Earlier this week Artificial Lawyer attended the Alternative AI conference in London, (and spoke a bit about legal AI there…), but the highlight was surprisingly not how law firms are making use of data and machine learning, but rather how other professions are.
What differentiated the Alt AI event was the way it brought accountants and consultants together with law firms and their IT and innovation teams.
This was refreshing and Artificial Lawyer spent time listening to those outside the legal village, in part because we can get a little bit too insular in legal tech land and not look over the fence into other sectors’ gardens to see what they’re growing on the AI tree and what we can learn from their approaches to data and machine learning.
So, out of a mass of speakers, we’ll just pick two sessions. The first of which was by Big Four, multi-service firm KPMG.
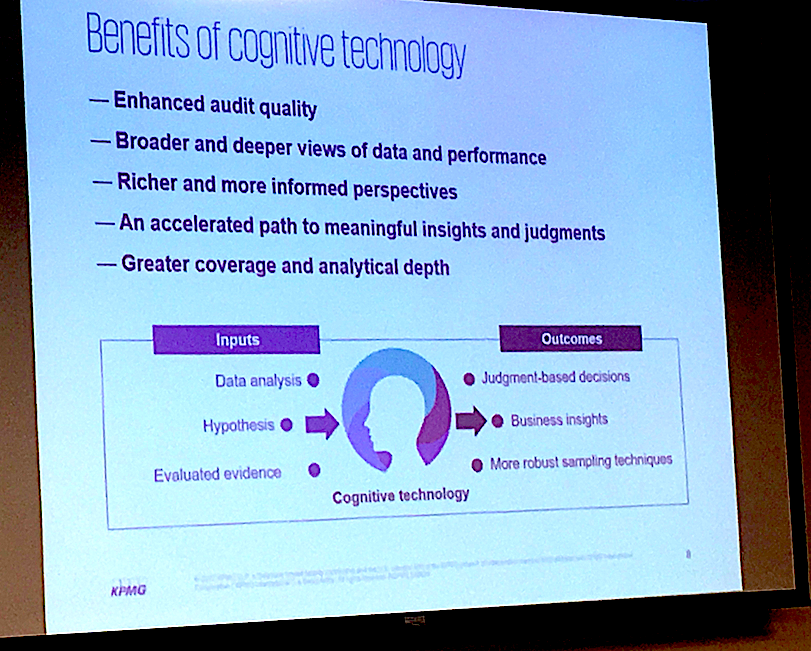
KPMG’s representative, Nick Frost, talked through one particular data-led tool they’re using to help banks speed up the approval of loans, namely their Commercial Mortgage Loan Assessment tool (CMLA), which taps IBM Watson’s AI capabilities, such as its natural language processing (NLP) tech.
While there is plenty of complexity on the back end of the CMLA, the front end looks surprisingly simple and easy to use, which perhaps is a testament to good design. It looks more like the interface for a credit rating site, but that was presumably intentional, right down to a score out of 10 in the top left corner of the dashboard.
To get a response the bank inputs a wide range of documents into the system, which when listed appeared to be in some cases up to 250 pages’ worth of written and numerical data. The algorithmic models that KPMG and IBM Watson have developed analyse, filter and extract the key information relevant to loan applications, compares it to standards and expectations for certain types of applicant, then gives the score.

The score also comes with the documents attached in a linked file and also a confidence level of how sure the system is. This shows that Mr Smith’s application is a 6 out of 10, with a confidence level of 80%, as opposed to Mrs Jones, who has scored an 8 out of 10, but with a confidence level of 70%.
In this way there is a totally transparent audit trail, so if anyone asks: ‘Hold on, your machine just denied me a loan? Why was that?’ The bank can explain why, or at least show they made an effort to be reasonable and logical about the process.
Of course, no automated approval system can be better than the models a business uses to gauge risk. But then, all humans have models with biases built into us, even if we don’t see them. So, perhaps the issue here is the time savings and perhaps also the consistency of the decisions.
Interestingly, the system has had to navigate the differences in British and US English documents. They are also feeding in third party information to help the system make a decision, including news feeds that may be relevant, e.g. news of a rash of a High Street shop closures that may impact the probability that a loan to a retailer should be granted.
And finally, although the tool gives you an approval/risk score, KPMG or the bank can still go back and change it. I.e. this is not a purely ‘computer says yes/no’ scenario. The algorithmic justice of the loan approval process can be ignored.
Overall, a great example of modelling historical data, tapping NLP to analyse new documents, then using a rules-based approach to create a useable outcome, in this case a risk/approval rating.
And now for the second example, which was provided by property consultancy JLL, which looked at commercial real estate valuations.
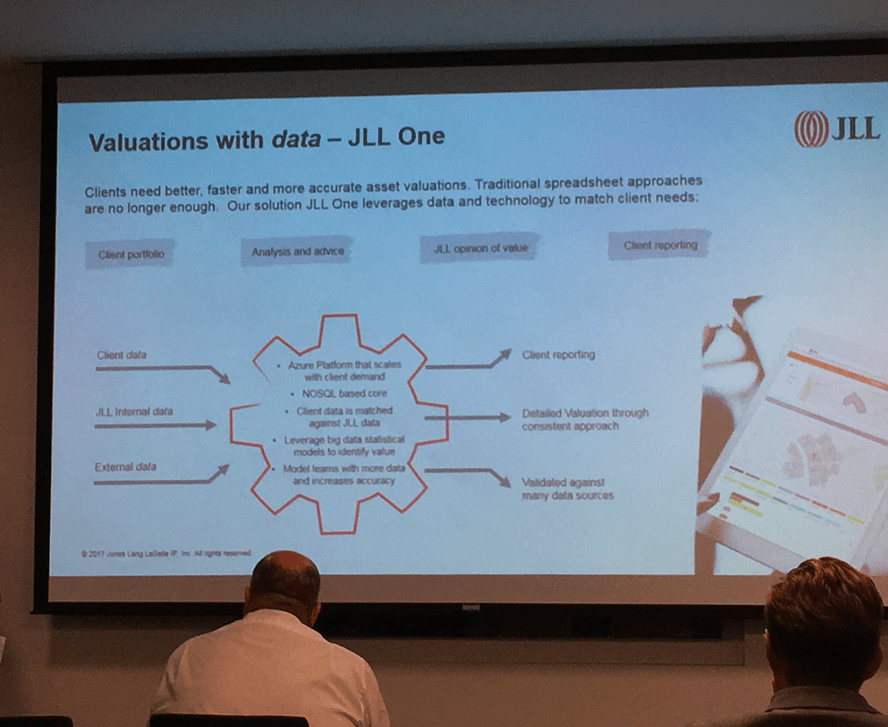
The consultancy’s Andy Crow explained how they had created their own data-driven solution called JLL One, built on the Microsoft Azure platform. In several ways this is not dissimilar to what KPMG is doing with loan analysis, i.e. take data, build models, compare new request versus models, then provide a reasoned outcome.
And JLL certainly are packing in a lot of data to make their assessment. They feed in the client’s data, JLL’s own data on valuations and also any other third party data that can help, e.g. local government information about land values and uses. There is also the option to feed in news and market information to help come to an assessment.
What this provides is several things, says JLL. Building algorithmic models that can then be used to make assessments of incoming matters allows firstly speed, which one would expect, but it also provides a consistent approach for their clients. A property company won’t get two different interpretations depending on which consultant they ask.
There were also some good insights into how to approach the development of machine learning tools from JLL, namely: don’t start with the tech. The message was this:
- Clearly define the business need, (in this case faster property valuations for clients).
- Define and find the data that will be needed to make improving this process possible (as without a ready supply of data to build models and to feed into the system then it’s not going to be much use).
- Consider what sort of tech you really need to solve this problem and create value from this data, (e.g. if it’s all just standard, structured numerical data provided in neat spreadsheets, do you really need to think about AI solutions? If there is a lot of complex, unstructured data that requires cognitive tech, then maybe you will need an AI solution.)
Artificial Lawyer would add a fourth point that goes beyond data, which is: think clearly about how you add the rules-based elements. Collection of data is one thing, but how what is extracted is then used is the real clincher – though at present everyone seems to be obsessing only about the data. Naturally, the data is key, it’s ‘the fuel in the engine’, but it’s the rules-based elements ‘of the engine’, i.e. the ‘moving parts’, that create the final value.
And on that point, we’ll say farewell to Alt AI and its multi-service range of speakers and look forward to next year’s event.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.