
It’s Not A Legal Snowflake!
By Catherine Krow, CEO of Digitory Legal, the litigation budgeting and cost management platform.
Ask litigators how much a complex litigation matter will cost and they will respond with some version of ‘it depends’.
This answer is deeply ingrained in many lawyers, who believe that each case is unique, like a snowflake, therefore it is impossible to predict the costs.
For years, clients accepted this non-answer. Then, the market evolved.
Today, ‘it depends’ estimates are not good enough. After the market crash of 2009, corporate clients began applying an unprecedented level of business discipline to the practice of law. Slowly but surely, this pressure generated a rising tide of alternative fees, competitive bidding and budget caps that now reaches even the most high value work.
To succeed in this environment, law firms must cost out litigation matters more accurately and competitively than they have ever done in the past. In fact, getting this right is mission critical.
Fortunately, modern technology can provide an unprecedented degree of transparency and precision in cost estimation. The key is using artificial intelligence to unlock the predictive power of billing data.

Measure The Unmeasurable
Law firms’ inability to accurately forecast costs frustrates and confuses clients. After all, the firms claim to be experts who have worked on big, complicated matters time and time again. Given that experience and the firms’ access to piles of historical billing data, clients expect outside counsel to predict legal fees correctly.
 But many firms forecast litigation fees poorly. The reason for this is not the unpredictable nature of litigation. The real problem is this: in its natural state, legal billing data is virtually useless.
But many firms forecast litigation fees poorly. The reason for this is not the unpredictable nature of litigation. The real problem is this: in its natural state, legal billing data is virtually useless.
Historical billing data is of little help in future cost estimation for two reasons.
First, you cannot use past costs to estimate future fees without real insight into the scope of those prior matters, e.g.:
- What volume of documents were reviewed?
- Which motions were filed?
- What experts were needed?
- How many witnesses were interviewed?
However, the industry standard codes for litigation billing are very high-level and provide no information about matter scope or the unit costs for each task.[1]
Second, the timekeepers (or ‘fee earners’ as they are called in the United Kingdom) who bill time on litigation matters typically code their time entries inconsistently and wrong.
Put these two problems together, and – to use a construction analogy – it is like seeing cost of a house but having no idea how many square feet, floors, bedrooms or bathrooms there are. And then having all the plumbing work coded as drywall. The number tells you nothing.
Today’s technology can shed new light on dense and misleading historical billing data. The more visibility firms have into the past, the more accurately they can predict the future. Of course, nothing worth doing is ever easy.
The first rule of artificial intelligence is ‘garbage in, garbage out’. Thus, because lawyers code time narratives so poorly, their coding choices should not form the foundation of any technology.
To produce accurate and consistent results, the data sets used to train algorithms need to be coded by experienced professionals, preferably individuals who understand complex litigation and can see patterns in the data based on context. This process is time-consuming, expensive, and absolutely critical.
In addition, filling in the missing scope element means dividing data into more granular categories than the industry standards allow and clearly labelling it to allow for proper visualisation.
For example, rather than using the UTBMS standard ‘L330’ code for all deposition work, technology can help allocate the time associated with each individual deposition to that specific witness and track the number and type of witnesses to account for scope. (See e.g., Figures 1 & 2).[2]
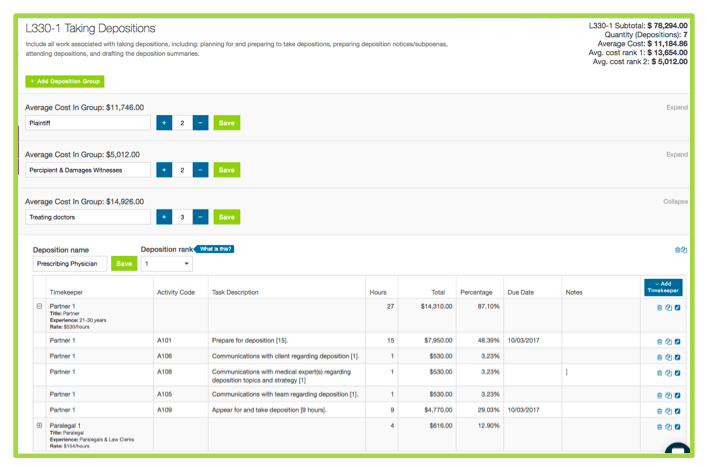
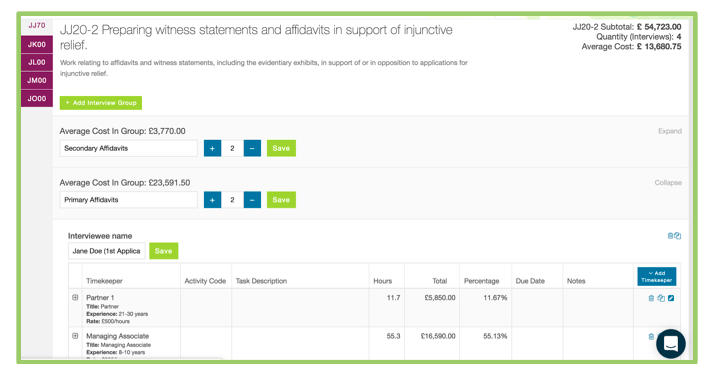
Using the Past to Refine and Predict the Future.
Once billing data is transformed and visualized, inefficiencies are easy to spot. With this insight, law firms and clients can better align resources and reduce costs where appropriate without compromising quality of service. This allows them to move past what matters did cost to what they should cost, building well-scoped fee arrangements that are less expensive for clients and still profitable for law firms.
Furthermore, even litigation ‘snowflakes’ will follow patterns. When artificial intelligence is applied to data at scale, those patterns can emerge.
The result: predictive cost models – such as complexity-scored budget templates – for different types of cases.

With the deep understanding of costs that artificial intelligence makes possible, perhaps the legal industry can finally shake its stubborn addiction to the billable hour model. So lawyers can stop obsessing over time and focus on their primary goal – the outcome.
About the author: Catherine Krow is the CEO of Digitory Legal, an award-winning litigation budgeting and cost management platform. Digitory Legal uses AI and analytics to transform billing data and to create predictive pricing models for complex legal work.
Prior to founding Digitory Legal, Catherine practiced law at top-tier firms for 17 years, most recently as a Litigation Partner at Orrick.
Notes:
[1]The industry standard billing codes for U.S. litigation is the Uniform Task Based Management System (UTBMS) litigation code set. In the United Kingdom, the new industry standard regime for litigation time recording is the Jackson codes. These code sets are referred to as the “L” and “J” codes, respectively.
[2]Data in figures is synthetic and should not be considered representative of actual costs.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.