
Pioneering doc review and analysis company, Kira Systems, has today launched a Q&A capability after many years of work, that will allow users to ask a question about a doc set and in return receive an NLP-based answer.
The move is in step with other legal AI doc review companies, such as ThoughtRiver and Eigen Technologies to name a couple, that have already launched a Q&A capability.
The reason why this matters is that lawyers have always wanted more from doc review and analysis systems, i.e. to go beyond having to wade through document sets and to simply be able to ask a question and get a (relatively) straight answer back.
In terms of market developments, the new system called Answers & Insights, also matters as it covers off an area some competitors had already made significant progress with. For example, Eigen has made their Q&A capability a central part of their offering for some time now. They’ve also done well as a company recently, winning work with more law firms, such as the major LIBOR/IBOR repapering project with Allen & Overy.
That said, Kira responded: ‘Answers & Insights is special. The difference between our version and Eigen/ThoughtRiver is Quick Study – our users can themselves extend Q&A using machine learning, while other systems may have answers functionality, they are very different if vendor data scientists are necessary to create new answers, or if rules-based.’
‘What Quick Study has shown over the years is that machine learning is better than [a rules-based approach] for scalability and robustness on unfamiliar docs, and allowing users to self-train with no developer skills required is very powerful,’ the company added.
Artificial Lawyer spoke to CTO and co-founder of Kira, Alex Hudek, about the major step that should help to deliver far deeper insights into documents for users of Kira, while hopefully also providing additional work efficiencies.
—
What has inspired Kira to build this Q&A capability? Was it a frequent client request?
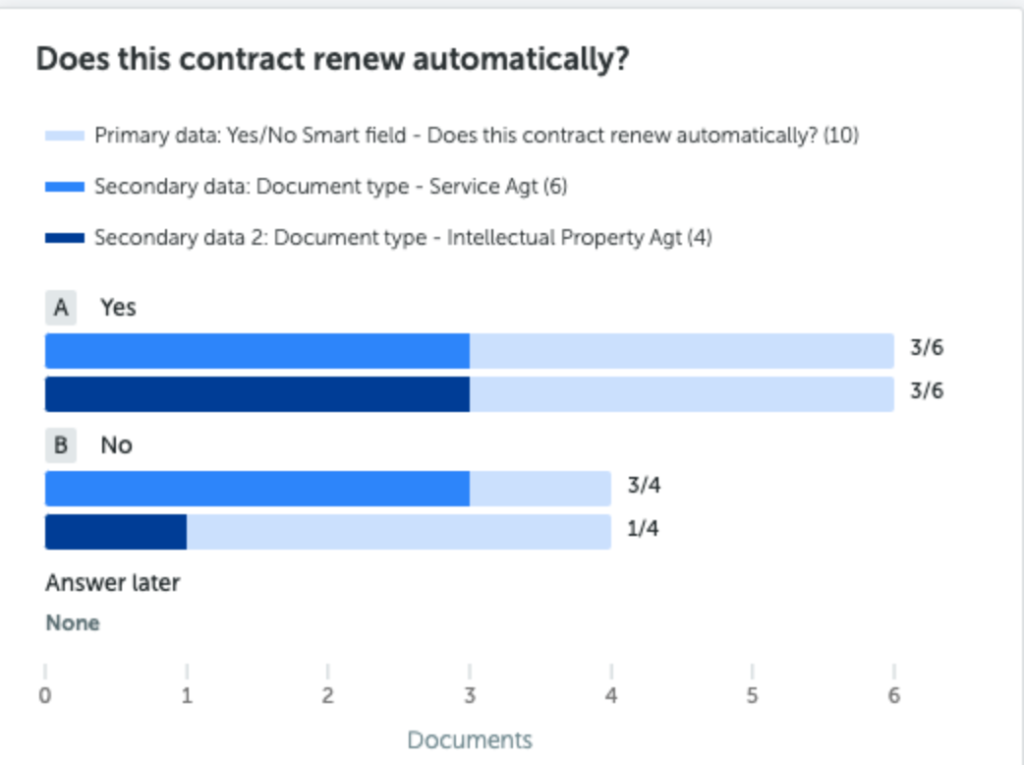
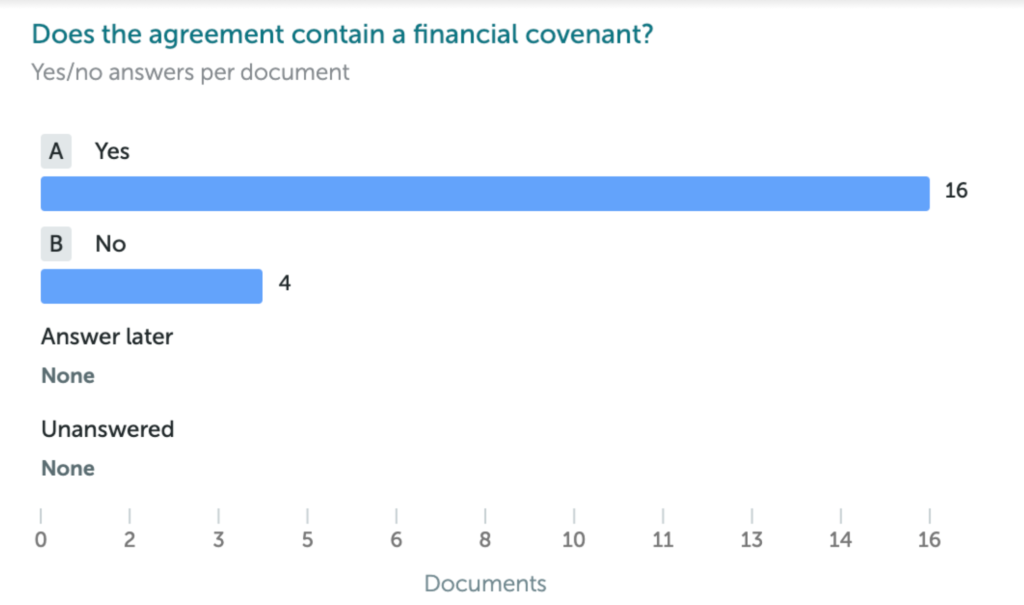
Clients have long asked for the ability to add multiple choice and yes/no type data fields to help them with their review. Though they were just thinking of being able to manually enter data, I don’t recall anyone making the leap that it’s possible to automatically answer them.
Ultimately we built this by thinking about the overall review process and creating something to help with the work that today is done after Kira extracts data. These question answering fields are trainable via Quick Study, our no-code machine learning platform.
What new technology, or techniques, needed to be developed by Kira to allow this Q&A system to work?
We developed a novel machine learning architecture that powers this feature. It has the same sort of privacy guarantees for the training data as our existing technology.
Does it also need training? I.e. you need to train the Q&A system on the docs to get accurate answers (as you would for normal clause extraction)……or can it just run accurately as soon as a doc stack is uploaded?
We do plan to ship out of the box functionality with question answering, but yes, it is also user trainable as part of Quick Study. As with our traditional smart fields, teaching the system is extremely simple. Just give it examples of questions with their answers and after providing enough examples the system will learn to do it itself.
Given that question answering is generally a more complex task than simply extracting text, it will require more examples than a traditional smart field.
Can this be used for just one doc, or many?
This is designed to answer the same question for many documents. Usually when you hear companies like Google talk about question answering, they are referring to a very different task. Specifically, the popular question answering deep learning models will answer ad-hoc questions about a single document, with the constraint that the answer must be text within the document itself. In contrast, our question answering task involves answering the same question over a collection of documents. The answer doesn’t need to be verbatim text within the document either.
What jurisdictions does this facility work in at present?
The question answering smart fields we plan to ship in the initial release are all English. Most of them are trained on US contracts, but include some Canadian and UK documents too. The underlying technology is jurisdiction agnostic however.
Would GPT-3 (if you could find a way around privacy issues) be useful in this type of application? [Note: see AL article, also by Hudek, about the pros and cons of GPT-3).
GPT-3 and other deep learning language models could be used to build technology like this. [But], our task is a bit different from the usual question answering task used in deep learning literature.
That said, you could definitely design a model that is built on top of a language model like GPT-3 that could answer a given question of the style we target. Aside from privacy, the challenge would be the amount of computing resources you would need to train the system for a particular question (AKA fine tune the language model towards the specific task).
It’s an open question whether GPT-3 could perform well on this task without extending the model and further training it. We don’t have access to GPT-3 to test. Given that question and answer pairs of sort the our clients ask are not typically found on the public internet, I suspect the system wouldn’t do great at them due to a lack of examples. But the only way to know for sure is to get someone who has access to test it.
—
And here’s a short video by Kira that gives another overview:
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.