
By now you’ve probably noticed that there is a new language model in town called GPT-3, and it has the potential to have a significant impact on legal tech – and many other sectors – especially in relation to applications that automatically read and produce text, for example document creation and legal research. But, it’s not all plain sailing and we should not get too carried away – as is already happening in some places.
Given that we need a bit of balance here, who better than Alex Hudek, the CTO and Co-Founder of Kira Systems, the NLP-driven doc analysis pioneer that really helped shape the market for machine learning tools in the legal sector, to provide a detailed overview of what it all means.
In this piece that looks at both the pros and cons, Hudek explores what GPT-3 can actually do and where it’s not so great. And yes, it does have some cons, see for example the privacy point, which is actually very significant. Enjoy.
—
GPT-3 is really interesting and has stimulated much discussion. But, there are big practical concerns that need to be overcome for us to use something like it in our technology stack, particularly around privacy and compute requirements.
I could see the functionality of these sorts of language models helping, so overall the answer to whether we will use this is: ‘Maybe one day, but more work needs to be done to address some practical shortcomings’. I’ll elaborate below on that and GPT-3 in general.
First, if you haven’t seen it, check out this list of links to various GPT-3 demos: https://github.com/elyase/awesome-gpt3. There are legal related demos there that are pretty amazing.
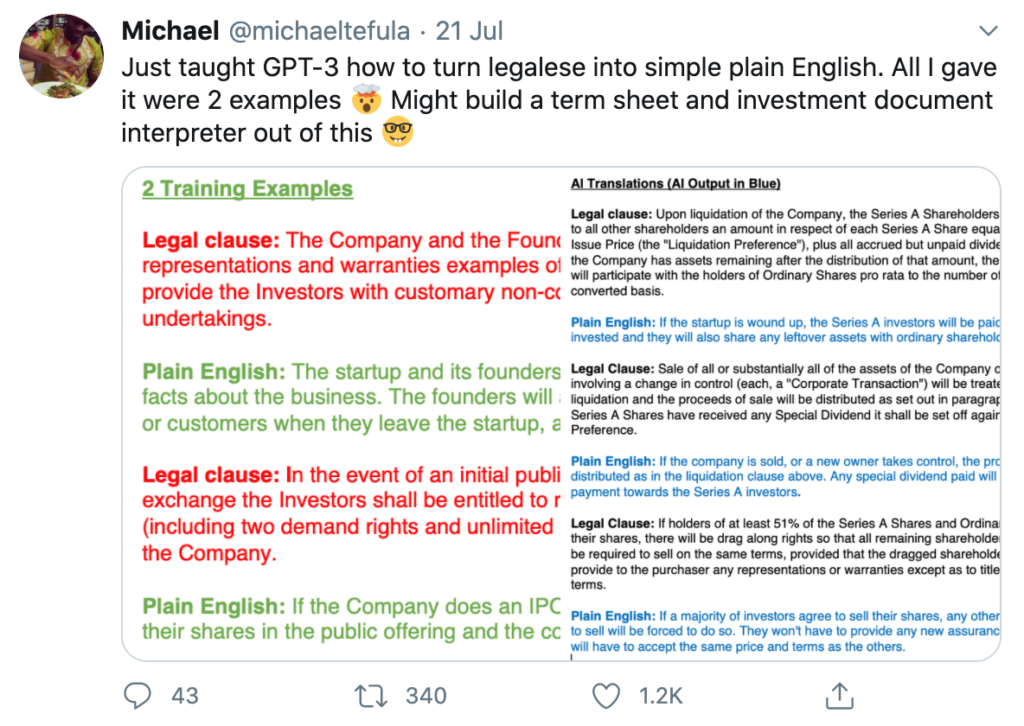
Overall, what is novel about GPT-3 is really just its size. It’s been trained on a substantial portion of ‘The Internet’ and is the largest language model trained to date. The actual underlying technology isn’t that different from previous language models.
At its core, all a language model does is predict the next word given a series of previous words. There are different techniques that are used to convert a language model from this simple task to more useful tasks such as answering questions about a document or summarising a document.
Usually, the best results are achieved by something called ‘fine tuning’. This is where you modify the architecture to get it to do a new task, then continue training it on 100-1,000 new examples to ‘tune’ it to the new task.
The second novel thing about GPT-3 is that they didn’t use fine tuning. Rather, they used a simpler technique where you condition the model towards mimicking a particular behaviour by giving it just a few examples.
The surprising part is that thanks to its increased size, GPT-3 can often come close or match results that have been achieved with fine tuning, without fine tuning. This is important because fine tuning is expensive when it comes to computing cost. Particularly so as the model grows in size.
Training GPT-3 was estimated to cost more than $4m worth of compute time, and that’s the low side guess. Fine tuning doesn’t cost that much, but it is still costly.
In fact, no one has tried fine tuning GPT-3 yet, when they do you’ll see far far better results than we see even today.
Without fine tuning, GPT3 is in fact not as good as smaller previous models on many tasks, and often only matches them on other tasks. That’s not to detract from the achievement at all, as I said, being able to get close to or match state of the art without fine tuning is huge. But it does matter when we start to talk about practical applications of this technology.
To your question ‘will this be useful in practice?’, the answer is yes in some tasks, no in others. By not requiring fine tuning, in places where it’s matching state of the art it may become easier to deploy because you don’t have to do expensive fine tuning to get it working. Today, the only way to get access to it is via an API from OpenAI. Unfortunately, this means that any organisation that is highly privacy focused is unlikely to use it, including Kira Systems.
But, even if we had access directly to the model there would be challenges. First, it’s unclear if the model retains data it’s been shown during its simpler training period.
This would require research, as our customers are often required to delete training data, and if a model retains a portion of that data in a way that can be extracted, that would be a huge problem.
If we had to fine tune the model, assuming it was practical from a compute standpoint, this problem would get even worse. It’s well known that these language models can generate text that looks exactly like the documents it was trained on!
In fact, most popular deep learning systems suffer these privacy issues with regards to training data. So for us, this prevents us using them. That said, we still do experiment with them to see how accurate they are. At some point the accuracy gains may make it worthwhile to try to solve the privacy issues.
Talking more generally, another issue with GPT-3 and similar technology is the source of the training data. Particularly, for legal, has the model been exposed to the sorts of contracts we would need it to work on?
We can be certain that GPT-3 hasn’t seen non-public data, that could mean that it will be less effective on the types of documents that are typically not public.
But, it’s also not clear if they even included EDGAR data when training GPT-3. Now you could do this, if you had a few million to retrain it. So it isn’t a fundamental limitation, but something to keep in mind. You probably can’t train it on private data without overcoming the privacy challenges.
The other issue for some tasks will be bias. Being trained on the internet, the data has inherent biases. E.g. that could be racial biases, biases based on gender, or other.
The amount of training data does mitigate this a bit, but it’s still a big issue and one of the main problems OpenAI is trying to overcome as they release the model for use by others.
Typically you’d try to ‘fix’ the training data by removing bias, but in this case that isn’t practical. So, as far as I know OpenAI is exploring approaches that filter results instead. You can be sure that this model is capable of generating some pretty ugly language!
Finally, it’s worth keeping in mind that although this model often looks like it’s doing some pretty sophisticated reasoning, that can be an illusion.
Take arithmetic for example. They tested its ability to add numbers and were amazing to find that it could! However, as you make the numbers larger, suddenly the model can no longer do arithmetic. This is likely because it’s simply memorised addition tables for small numbers.
One way to think of it is that in a way it has ‘memorised’ the internet. The implications of this are that you’ll get extremely impressive results for situations where it can just regurgitate something it’s already seen, but in novel or rare cases it might fail. This is not a property that you generally want in an AI system. It’s a form of overfitting in a way.
Where it could work:
1. Answering questions or finding results from public data. Legal research might be an area where it will make a big impact.
2. Generating text in situations where you have a human in the loop. Think Google’s auto-complete, but even more sophisticated. It has potential uses in contract drafting, but you’d need to make sure it has been trained on the right data.
Where more work is needed:
1. Privacy – These sorts of models are fundamentally not at all privacy preserving when it comes to the training data. They are explicitly designed to reproduce the data they see. This is a huge problem in many domains (and for us).
2. Compute cost – A model this big has significant compute costs, even just to run in prediction mode. As a point of comparison, we did some work comparing a much much much smaller deep learning model on training time. It was ~2800 times slower to train the deep learning model, and incurred 10,000x the cost in computing hardware in comparison to our core technology. For just predicting, the deep model in our study was probably 100x slower. This can be a real issue for practical deployments of this technology, and GPT3 is going to be even worse due to its size. It will be interesting to see what OpenAI eventually charges for access to their API.
3. Bias – not so much an issue for us, but definitely an issue for some use cases, especially where there is no human in the loop.
4. It’s probably not actually doing sophisticated reasoning, and might fail in rare or unique cases.
Overall it’s a very important piece of work, but won’t change most of the industry overnight. There are definitely a few tasks where it might have a bigger impact in the near term. Here at Kira we’re not planning on adopting soon due to the various shortcomings, particularly around privacy.
—
Thanks, Alex. An excellent overview of the pros and cons, especially for a company in the legal space. Let AL know what you think.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.
4 Trackbacks / Pingbacks
Comments are closed.