
You may have assumed that the market for contract-focused NLP analysis is pretty much saturated. But, money keeps flowing into companies that are not household names – yet. Take Cortical, which has just bagged $6m in Series A funding from Ezpada, a global commodity trading house, and earlier this year saw the European Investment Bank provide $9.1m.
Bagging around $15m in a year suggests a lot of investor appetite for this segment of the market still, even if Cortical doesn’t sell itself as purely a legal tech company, and has more of a focus on the corporate and management consulting world.
But, is Cortical different to what is already out there when it comes to contract analysis? Naturally, they believe so. First they are based in Vienna, Austria and have an office also in California. They talk in terms of NLU: natural language understanding, not NLP. And it started back in 2011 – around the same time Kira Systems got going – so it’s interesting that the Series A round has happened now, a decade later.
They also add that: ‘The company is working to enable semantic supercomputing: the ability to process streams of natural language content at massive scale in real-time through the use of hardware acceleration.’
Cortical has also patented an NLU technology ‘based on semantic folding and neuroscience’, which sounds exciting, but does its Contract Intelligence 4.5 offering, ‘which automatically and accurately searches, extracts, classifies and compares key information from agreements, contracts, and other unstructured documents like policies and financial reports’ do what others cannot?
Given the description of how it works (see below) it doesn’t seem that different. You’ve got your training data and your subject matter experts (SMEs), same as everyone else does. There are limits to what you can do with this formula.
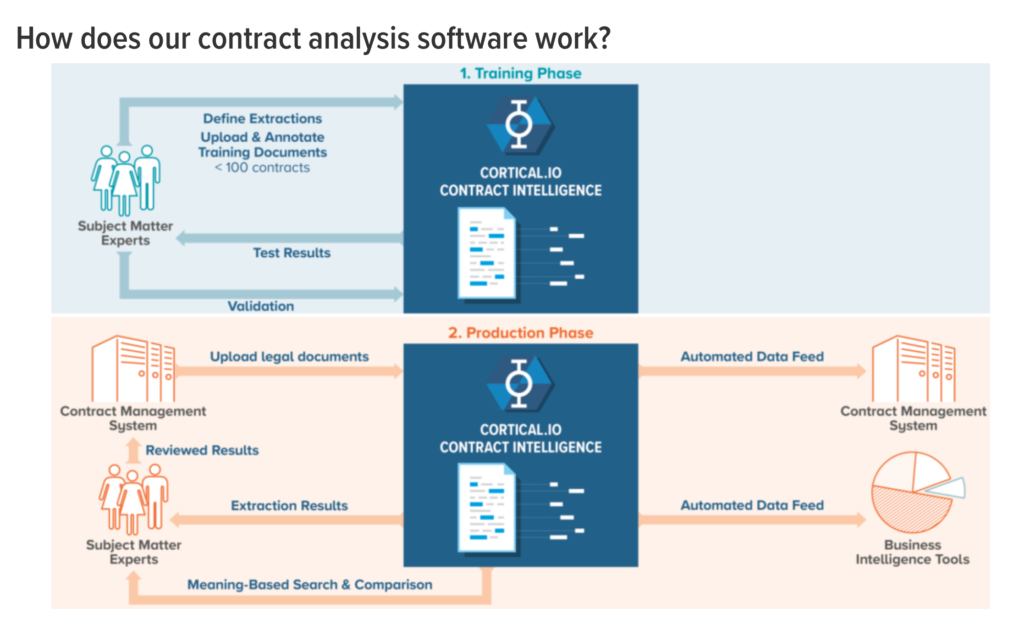
The one thing that struck this site was the claim that they could get going with just 100 document samples.
‘The system can be trained by SMEs starting with as few as 100 documents. Once the SMEs have defined custom extraction targets and annotated a few documents, they can train the system to automatically perform the extractions. SMEs also have the ability to review results and can continue to fine tune the system as part of a continuous learning process,’ the company states.
Now, much depends on what you are trying to do, so a very small sample can be a good enough beginning data set in some limited circumstances. But, if you are looking for complex unstructured data extraction, e.g. clauses, and across a range of documents that could be quite dissimilar, then 100 documents seems like a small set to start with.
Any road, the key takeaway here seems to be that 1) there are still plenty of independent NLP doc analysis companies out there that could be of use to legal teams and law firms – and in fact Deloitte Legal has had a go with Cortical in the past, and 2) money is still pouring into this segment.
Thomas Reinemer, COO at Cortical, added in a statement: ‘We are very excited to bring on a new investor to fuel our growth. This funding, in conjunction with the earlier funding from the European Investment Bank, will allow us to expand our efforts to market our proven solutions.’
‘We will use the funds to increase our sales and marketing initiatives,’ he added.
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.