
Artificial Lawyer recently caught up with Aniruddha Yadav, Founder and CEO, Gauge Data Solutions, which has created Casemine, a legal AI start-up taking the battle to build the leading case analysis system to the US – and soon the UK – from India.
Aniruddha talks us through how he got started, the benefits of an India-based legal tech team, how Casemine stands in relation to Casetext and ROSS’s new EVA, and how the clients are responding.

When and how did CaseMine get started? What was the inspiration?
I have always been a quantitative type and have always had fun in using mathematics to understand the real world. You know about the buzz that data science, Big Data, Artificial Intelligence, Machine learning, are creating and measuring up to.
Well before it became mainstream (circa 2012), us quantitative types (theoretical physicists, applied mathematicians, computer scientists etc) were already using the mathematical and computational machinery that today we call data science routinely in our own academic pursuits.
While at Mount Sinai as a postdoctoral fellow in computational neuroscience, I was using mathematical modelling and computation to understand a very special type of complex network— a network of neurons known as the human brain. It turns out that our brain is amazingly complex and a lot of smart people will make careers out of trying to understand how it works and still probably we will never know enough! But, along the way we may learn interesting lessons about the mathematics describing the underlying complexity that may become useful elsewhere–on perhaps simpler networks!
One fine day, back on vacation in India, I happened to have a conversation about our ailing legal system with my uncle, Justice Jainarayan Patel (then Chief Justice of Calcutta High Court), which sort of got me thinking about how what we call “ data science” may be of help. And then it occurred to me that our legal system, and any other legal system based on English common law is in fact also a network– that of case laws that cite existing cases laws as precedents.
Can the data science of networks be leveraged here to make legal research (the search for applicable precedent within the network of case laws) less time consuming and more efficient? The answer is yes! And this thought gave birth to casemine a couple of years down the line (around 2014). Casemine is owned by Gauge analytics, a boutique data science consultancy founded by me after leaving Sinai.

Where is the company based? Is that an advantage?
We are based out of Noida, India. The cost of development and acquiring SMB customers is certainly an advantage if one is looking at a global product. Scaling higher is probably a different story!
You have a talent pool of world class engineers available at anywhere between 15% to 25% of what one would find in the Bay area. Sales is the most substantial component if you look at the typical cost structure of a SaaS company (as much as 40% of cost for most SaaS companies globally). In SMB and mid-market sales, Indian bases startups might have an advantage because there are low-cost call centers to acquire and support customers.
What does Casemine do?
Casemine is an AI powered legal information retrieval system catering to mostly a litigation focused audience. While basic keyword based legal information retrieval systems have been around for quite some time, what differentiates casemine from these systems is context based retrieval of information. One can use entire passages and briefs and any other legal document as input and our AI (which we endearingly refer to as CaseIQ) is capable of understanding the legal concepts presented and is then able to retrieve other documents with similar legal concepts.
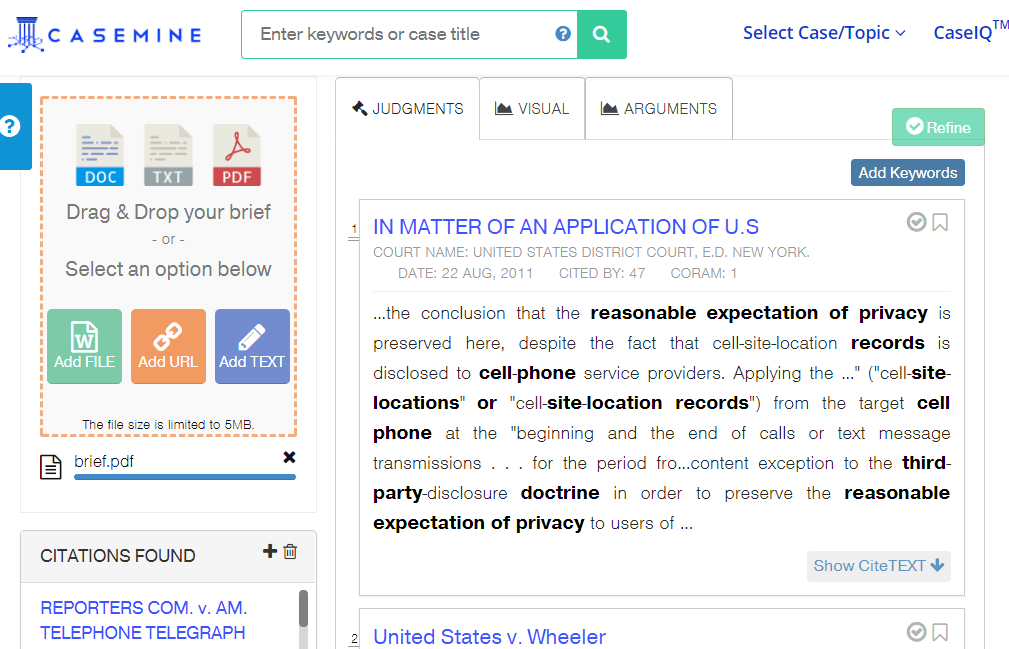
Given something as complicated as a brief, CaseIQ understands how facts, the causes of action, questions of law and other legal principles present within the brief interplay with each other to give a particular case its unique flavour and then prioritizes the retrieval of documents involving similar interplays. With something simple such as a passage containing legal language, CaseIQ is able to retrieve other authorities that might contain similar language.
We all know how parallel computing transformed industry and academia alike and the kind of advantages it brings over traditional serial computing. In some sense, contextual retrieval parallelizes legal research. No more entering several keyword combinations sequentially, rinsing and repeating (although this might be necessary in certain situations), just let the AI understand what you want and let it retrieve it.
Right now CaseIQ retrieves primary case law (judgments / opinions) and citation contexts (which we call citeTEXT). It will soon be able to retrieve relevant briefs as well as secondary material.
Built around the CaseIQ core, we have several other interesting features that let you further filter and organize / analyse the retrieved information.
- We have a visualization tool that lets you view how relevant precedents evolved over time and how cases cite each other. This is available both in the US and India.
- We have a JudgeIQ module that lets you zero in on what a particular judge has opined about cases with facts and legal principles matching those present in an uploaded brief with just one click. This is something exclusive to Casemine and is available both in the US and India.
- We have a MotionIQ module (specific to the US). It filters CaseIQ’s recommendations by motion type. Again, to my knowledge only casemine offers something like this.
A lot of products let you filter keyword search results by motion or judge, but we are the only Ai powered/ contextual search that has these filters. This is the first of its kind product crossover between “legal analytics” and “legal AI”. A crossover of this kind is perhaps a prerequisite towards building an intelligence that is able to accurately predict case outcomes.
What countries is this for?
We launched Casemine in India around a year and a half back. We just came out with CaseIQ’s US variant and plan to have a UK variant soon, followed by all commonwealth countries that share the common law heritage.
Is this similar to Casetext or ROSSs new Eva tool?
Broadly, a legal context retrieval system has two regimes of operation. A large document regime that includes briefs, judgments, pleadings etc and a passage/paragraph regime with smaller text blocks.
To my understanding, EVA in its current iteration is limited to the small passage regime. EVA annotates an uploaded brief by automatically recognizing cited authorities, but that is done in the background by CaseIQ and CARA too as it is a prerequisite to retrieve something more meaningful.
Casetext’s CARA gives decent results in the large document regime, but needs the presence of citied authorities (other case laws or statutes) within the uploaded document in order for it to be accurate.
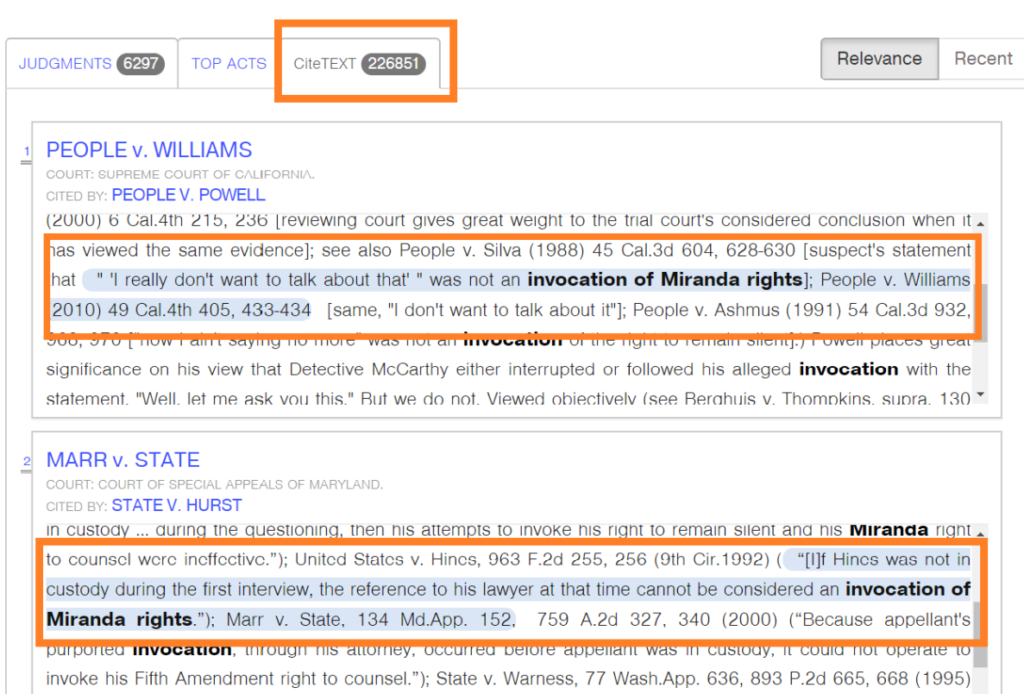
CaseIQ works well in both regimes as it does not need cited authorities for the algorithms to zero in on relevant information, although citations are leveraged to improve accuracy, if present.
Talking specifically about large documents/briefs, there is some overlap in results between CaseIQ and CARA. This overlap seems to be more in densely litigated areas of law where precedents are plentiful. The number of relevant results are also about the same. Thus, in densely litigated areas of law both CaseIQ and CARA come up with similar number of relevant results with a significant overlap too.
CaseIQ tends to have a larger number of relevant results in areas of law where case laws are sparse. This is perhaps because CaseIQ’s algorithms are somewhat citation network agnostic.
We are also able to filter our results by motion type and judge something which casetext has not done yet.
Casetext recommends briefs. We do not do this yet although we will have this feature soon. Of course, it would be great if someone neutral compares CaseIQ and CARA.
What do clients say?
The response has mostly been encouraging since gains in productivity and efficiency that our technology enables are pretty easy to see. We often get quotes like “Wow it took me a week to find these cases and you did it in a matter of minutes and all I had to do was click a button”.
Sometimes we do have to do a lot of educating to dispel incorrect preconceived notions about AI. Typically, mostly senior lawyers and law school professors/deans may have a view that AI will spoon feed their associates/ students, not allowing them to hone their research skills.
We have to then promptly remind them that harnessing AI to research is the new kind of skillset that needs honing, the kind of skillset that will make your associate/student learn faster and become more productive and efficient.
Potential clients are definitely becoming more aware about technology.
What next? How is funding going?
It is still early in the game for us in the US market. To get things rolling, we will be soon incorporating in the US and will have an office in the bay area. Our UK launch is also nearing, so you should be able to see CaseIQ’s UK variant soon. Casemine is supported by its parent company Gauge analytics. As such we haven’t yet felt the need to go in for external funding.
Thanks very much Ani!
If readers would like to see a short video about Casemine, please check out the presentation below.
https://www.youtube.com/watch?time_continue=7&v=jKJei12vGbI
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.
2 Trackbacks / Pingbacks
Comments are closed.