
LegalMation, the litigation-focused startup that has pioneered the use of Natural Language Generation (NLG), initially to produce first draft responses to discovery requests, has developed a new suite of tools that includes cost analysis and lawyer comparison capabilities.
Artificial Lawyer spoke to James Lee, co-founder and CEO at LegalMation, about the diversification of the platform.
Lee explained that the system can now help lawyers do automated budget analysis of what a matter should cost, and also help to pick the best lawyer for a very particular type of case.
To do this they’ve put the emphasis less on NLG and more on NLP, i.e. processing unstructured data and extracting relevant information. As part of the development of this new range of capabilities they have worked with inhouse legal teams, such as that of retail giant, Walmart.
The goal, as with all process automation in the law, is to reduce costs by minimising manual labour, to improve accuracy and data insights, and generally increase efficiency. Companies with significant legal spend will no doubt find this of interest. Law firms looking to speed up basic litigation work that is non-billable, or highly discounted, may also find value here.
‘To do a budget analysis a lawyer typically looks into their DMS and tries to find between three and five similar cases,’ Lee explained. ‘They try to find something that looks similar and then take the billing data from those cases. It can take about a day to do this. We can do this in a few minutes.’
Lee explained that to do this they have created a very detailed taxonomy of matters that they believe is far more granular than what SALI, the US-based legal standardisation project, is building (see story). This allows them to accurately predict what cases should cost.

‘We capture 500 unique types of legal cases,’ Lee added and said that the data can be from complaints filed in court, law firms and inhouse teams.
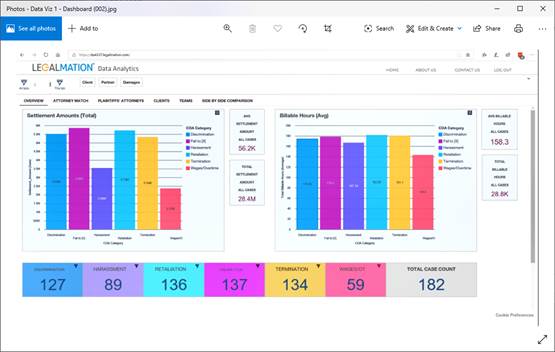
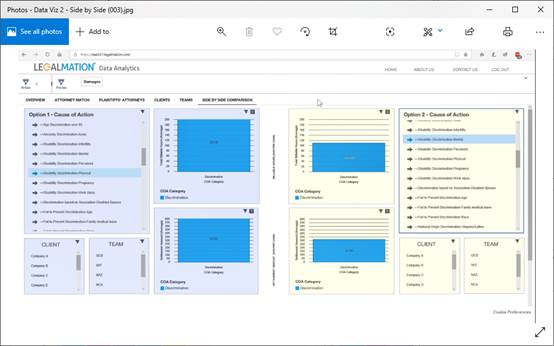
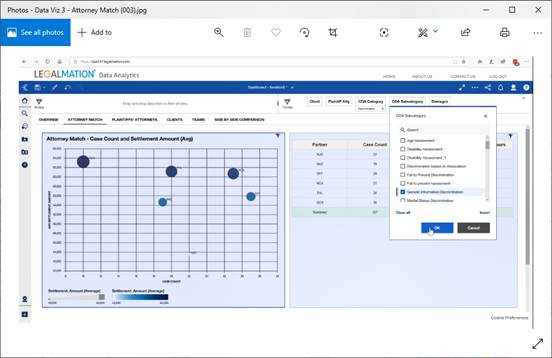
They also can compare the performance of law firms, individual lawyers, and compare against their costs and also how fast they are at completing a case (see examples below).
This is another example of taking legal data and applying NLP to create value. And again, this is not magic (see story on Litigate), it’s just thinking through what can be delivered from a data set and then applying software to provide that insight.
‘We can filter the top five lawyers in each type of case and that can give a small advantage against an opponent,’ he added. ‘You can do a risk assessment.’
Artificial Lawyer mentions others who have tried something similar in the past, including Premonition. Lee responded that they are working directly with inhouse legal teams to obtain data, for example, not just scraping public data.
‘Why are there no trading cards for lawyers?’ he asked rhetorically – and that’s a good point. After all, directories have a limited use. This approaches the most ‘live’ data available.
‘What we are doing is like a credit risk score for lawyers, on cases, on legal costs,’ he added.
Artificial Lawyer then had to ask: is this a major pivot from how you started back in 2016 with the focus on discovery responses and NLG?
Lee said: no. For LegalMation this is just building out additional capabilities on their platform. ‘Making a discovery response was just the start,’ he added.
And, what about the other companies doing litigation research? Are you overlapping with them? Lee stated: no.
He pointed out again that they are working with firms and GCs, not just using public data.
‘We look at inside data from firms and GCs. Public data only takes you so far. Take insurance companies for example, they really have a lot of data.’
In conclusion, he added that he really hoped to see companies sharing more data around legal costs and law firm performance in the future. If every company could ‘plug in all their data’ he noted – which could be anonymised in terms of sensitive case information – so much could be achieved.
And that’s a great point. Although the market has been waiting for the largest companies to pool all their legal data for a while and it hasn’t really happened yet.
So where next? The company is running a Beta with Walmart, and are expanding the offering to other parties.
And will this catch on? Lee’s view is that it just makes sense to save money on this kind of process work and to have a granular taxonomy of case types that helps to reduce risk, and hopefully improves insights into cases and who is best to handle them.
In short, if this kind of tool can improve the odds of winning and/or reduce costs, why not use it?
—
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.
1 Trackback / Pingback
Comments are closed.